

Everything was going according to plan.
We had modeled the entire system. The architecture was solid. CQRS, fully event-sourced, clean boundaries between read and write sides. The team was confident. We could see the finish line.
Then came the Mike Tyson moment.
“Everybody has a plan until they get punched in the mouth.”
The Punch
Our business expert walked in with those three dreaded words: “One more thing.”
We need templating.
Not just simple templating - users need to upload their own templates and fill them with… basically everything from the project. Customer data, addresses, project details, status information. Everything.
For a second my heart sank. I´ve been there before.
The Trap Every Developer Falls Into
Here’s the thing about templating requirements - they expose a fundamental tension in your architecture.
Templates need access to {customer.email}, {billing.address}, {project.status} - they need to reach into every corner of your system. And if you approach this wrong, you introduce the mother of all coupling.
The worst thing you could do? Just read from every table you have to fill those templates.
It’s so tempting. The data is right there. Your read side has nicely populated relational tables with all the information you need. Just query them, fill the template, done.
And that´s exactly what was suggested by one developer. “No problem, we have all data..”
But the moment you do that, everything is glued together like concrete.
When we change the structure for the dashboard slice for a new UI feature, the templates break mysteriously…
Your project just failed. You maybe just didn’t realize it yet.
Why The “Easy” Solution Kills Your Architecture
We had built a fully CQRS-enabled system. The backend takes write requests and asynchronously populates relational tables used by the client. Write side and read side are completely decoupled.
Those tables on the read side? They’re tailor-made for specific slices - the dashboard UI, the reporting screen, the admin panel. Each one is owned by a specific feature, optimized for a specific purpose.
When the developer on our team saw all these populated tables, their instinct was immediate: “Perfect, let’s just query these for the template data.”
I had to stop them.
“We can’t touch those tables. They’re owned by specific UI slices. If we start querying them for templating, we’ve just coupled our template system to UI concerns. The whole architecture collapses.”
I’d explained CQRS separation before. I’d gotten the nods, the “yes, yes” acknowledgments. But this time was different.
This time, with a real feature, a real deadline, and those tables RIGHT THERE - so easy to just query - something clicked.
“Oh my god, you are right! I get it”
The Solution: Treat Every Variable As A Mini-Slice
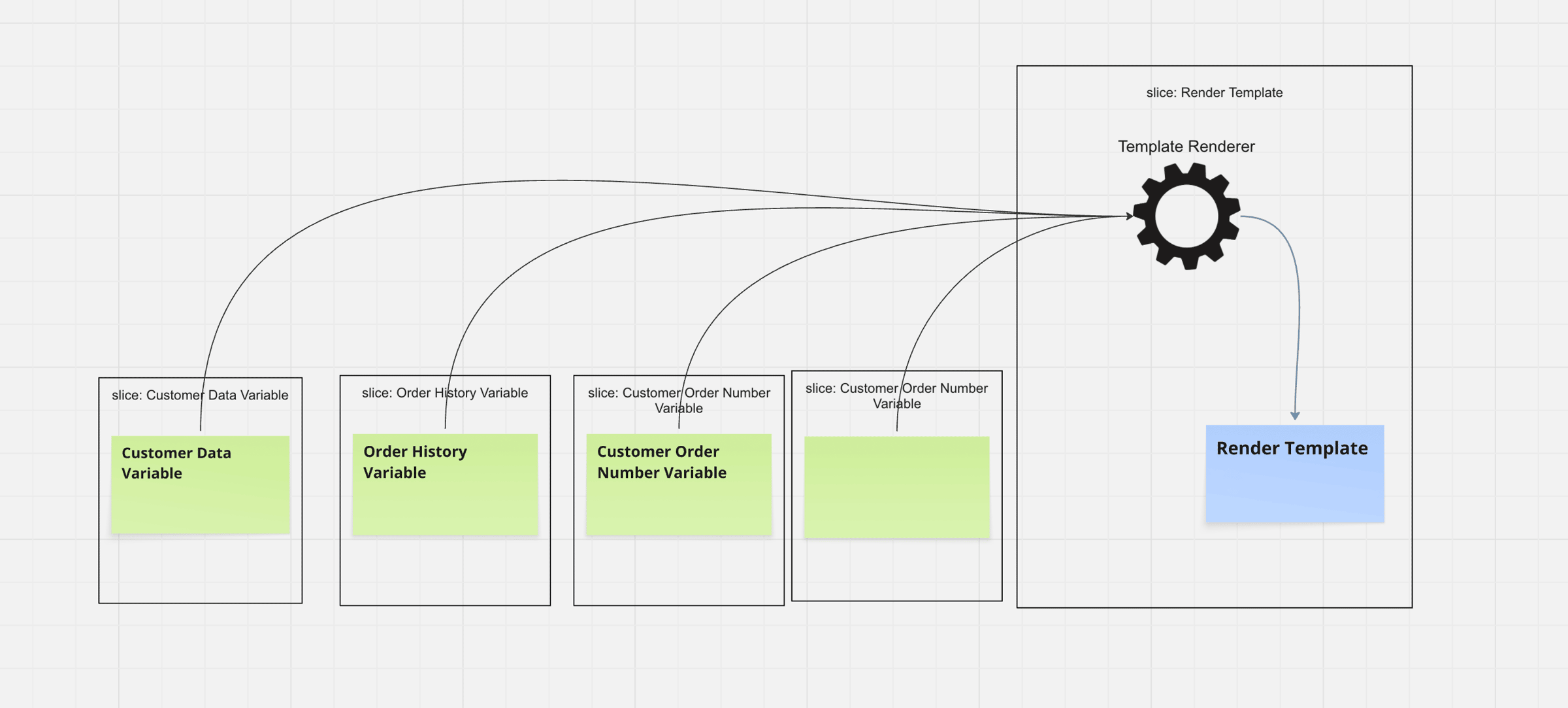
Here’s how we solved it in just four hours.
We had one concrete first use case: a user needed to create a prefilled onboarding document - a PDF sent to clients by mail, filled with customer data, addresses, and account information.
Instead of querying existing tables, we built dedicated read models. One for every template variable.
Let’s say we have a {client.address} variable. We create one read model that listens to:
- ClientAdded
- ClientDeleted
- AddressAttached
The read model doesn’t just store the data - it delivers a pre-rendered string ready to drop into the document. When the template engine hits {client.address}, it gets “123 Main St, Berlin, 10115” - formatted, ready to go.
The template renderer? Dead simple. Just string replacement. No logic, no formatting rules, no decisions.
The Beautiful Part: Infinite Extensibility
What happens when they come back and say “actually, we need the address formatted differently for international clients”?
Then it’s just another read model. Clearly laid out in the Event Model, verified using Given / When / Thens.. Business as usual. We always work like that.
{client.address.international} - new read model, listening to the same events, different formatting logic. Done.
No refactoring. No risk of breaking existing templates. No database schema changes. No coupling.
Right now, most of our variables read directly from the event stream. But if performance becomes an issue for a specific variable, we can easily change that one to precompute data and store it as JSON for rendering.
Each variable can evolve independently based on its own needs.
Why This Converted A CRUD Believer
We´ve built this whole solution in just four hours. Modeling the “Template-Variable-Slices”, and then just implement them one by one.
In the meantime - one developer implemented the Rendering Slice - just take those Read Models and apply them to a template.
They saw the pattern:
- Every variable is its own mini-slice
- Each read model has clear given-when-then behavior
- Adding a new variable follows the exact same pattern
It wasn’t magic. It was teachable, repeatable, and predictable. As always.
They could see exactly how to add the next variable without me holding their hand.
That’s the real power of event sourcing - being able to answer tomorrow’s questions today. Because we captured all data as events, we can easily access it to build anything tomorrow we didn’t know we needed today.
These Requirements Will Come
Templating is just one example. But requirements like this - the ones you couldn’t plan for, the ones that need access to everything - they will come. Dashboards, Reporting.. you name it.
This is when your architecture truly proves itself.
Not when everything goes according to plan. But when you get punched in the mouth, and you’re still delivering.
Learn Event Modeling from the experts
Join the Event Modeling Hands-On Workshop on March 16/17 — learn how to design systems that are honest from the start.
Want to learn how to apply Event Modeling and Event Sourcing in practice?
Follow the Online Course “Implementing Eventsourcing” - comes with a Lifetime Event Modeling Toolkit License.