I personally think that with Event Modeling we have one of the most important tools for documenting and developing complex software systems of recent years in our hands.
Why? Because it’s so simple and yet it works.
That’s why the company Nebulit focuses on this model in development.
The model was defined by Adam Dymitruk and first described in this blog.
In this article, I’ll explain what Event Modeling is and why I believe the approach is the right one for documenting and developing maintainable software systems of any size.
Event Modeling - Building Blocks
Event Modeling is initially a very simple way to describe the functionality of a software system in detail and explicitly takes the factor “time” into the model.
The basis for this is the simplest model that describes every software.
Action => Business Logic => Reaction
Or represented differently.
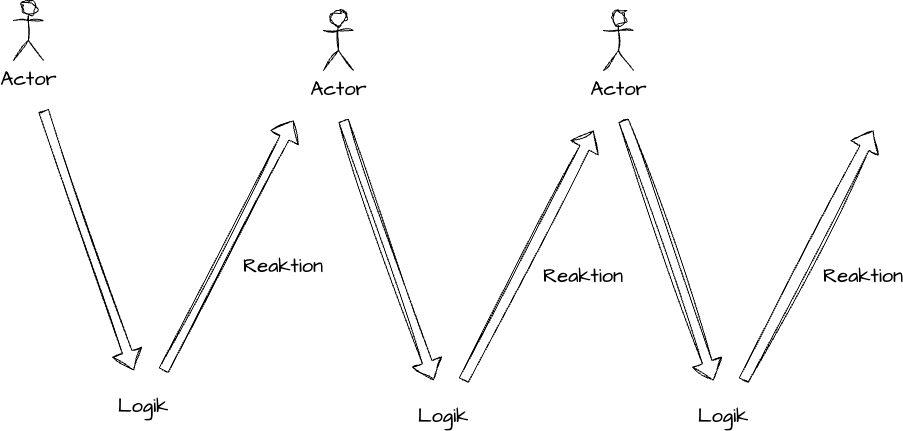
Instead of trying to define a model that describes our business model as precisely as possible (and is nevertheless inevitably wrong like every model), we initially completely forego defining a “model” and focus on actions, business logic, and reactions.
The building blocks are Commands (blue), Events (orange) and Read Models (green).
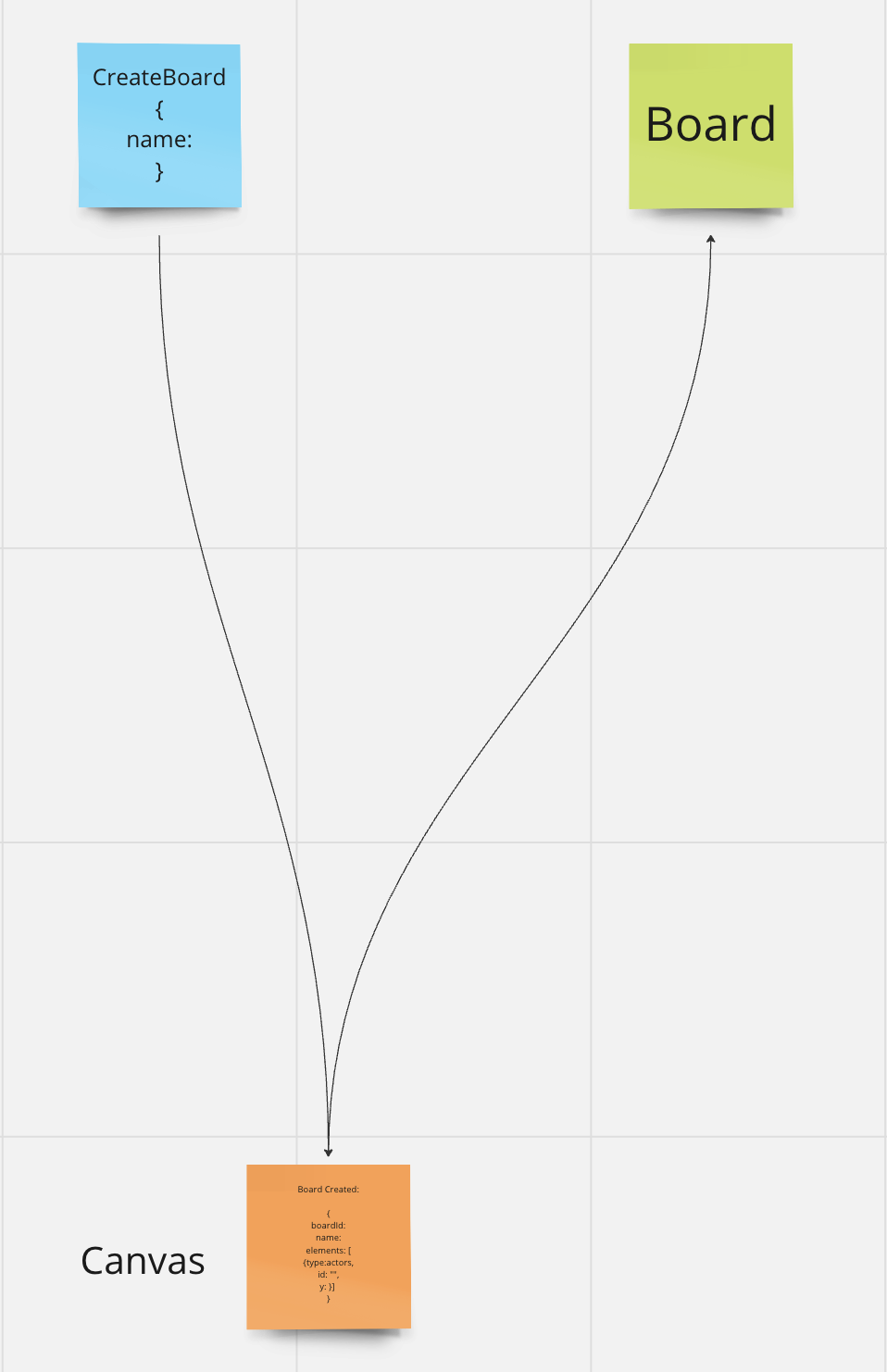
Event Modeling Building Blocks
Commands
Commands are actions that cause a change in the system. Every method of an API can in principle be considered a Command.
Changes in the system can only occur through Commands.
Events
Events (business events) are always the result of a Command and are facts that happened in the system in the past. We therefore formulate Events in the past tense.
Examples are:
“Order Processed”
“Customer LoggedIn”
“Process Cancelled”
Read Models / Projections
Read Models are simple and dynamic models that are generated from Events.
With Read Models we provide data for, for example, a UI or automations in the system. Each UI typically has its own lightweight Read Model.
An Example
With this technique alone, systems can be described incredibly precisely in a way that both a developer and the business side understand exactly “what,” “when,” “where” happens in the system.
Let’s do an example?
In an e-commerce application, the customer selects a product and puts it in the shopping cart. So the Command is Add Product to Cart

This Command is processed by the system (business logic checks whether the product even exists, whether we sell it, whether it’s available).
The actual implementation doesn’t matter. Whether these are microservices, monoliths, serverless workloads… the process is always the same
If the Command was successfully processed (and only then), we model the “fact” that a product was added to the cart as an Event (we store nothing more than this fact in the system)
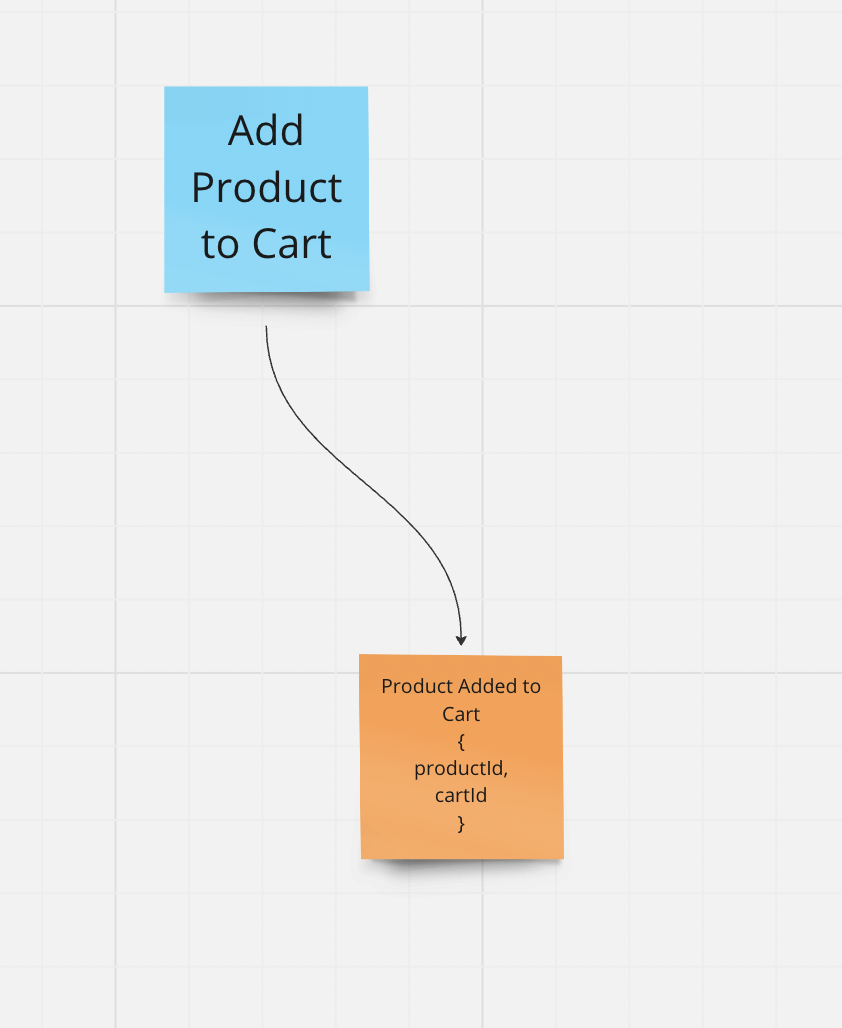
The “reaction” could now in turn be the display of the cart with the newly added product (and the prices). For this we need a simple Read Model or projection for the shopping cart.
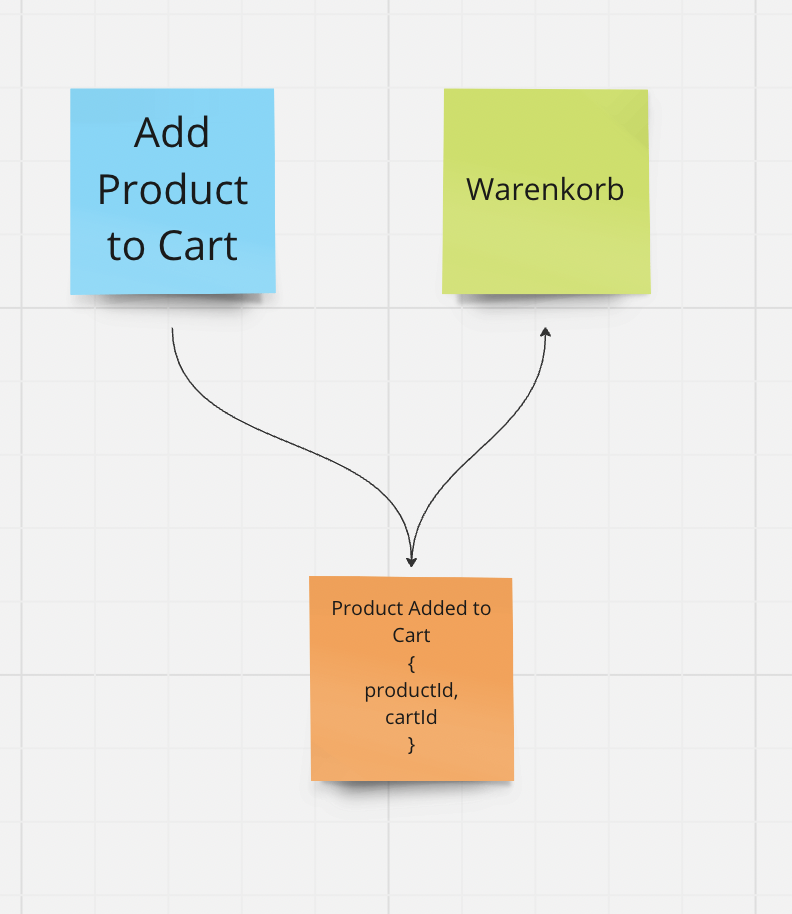
The Read Model “calculates” itself from the “facts” (Events) in the system.

From this simple example we see that two products were added, but also one product was removed. The Read Model would therefore only have one product for display.
Correctly represented, we would have this sequence in the Event Model.
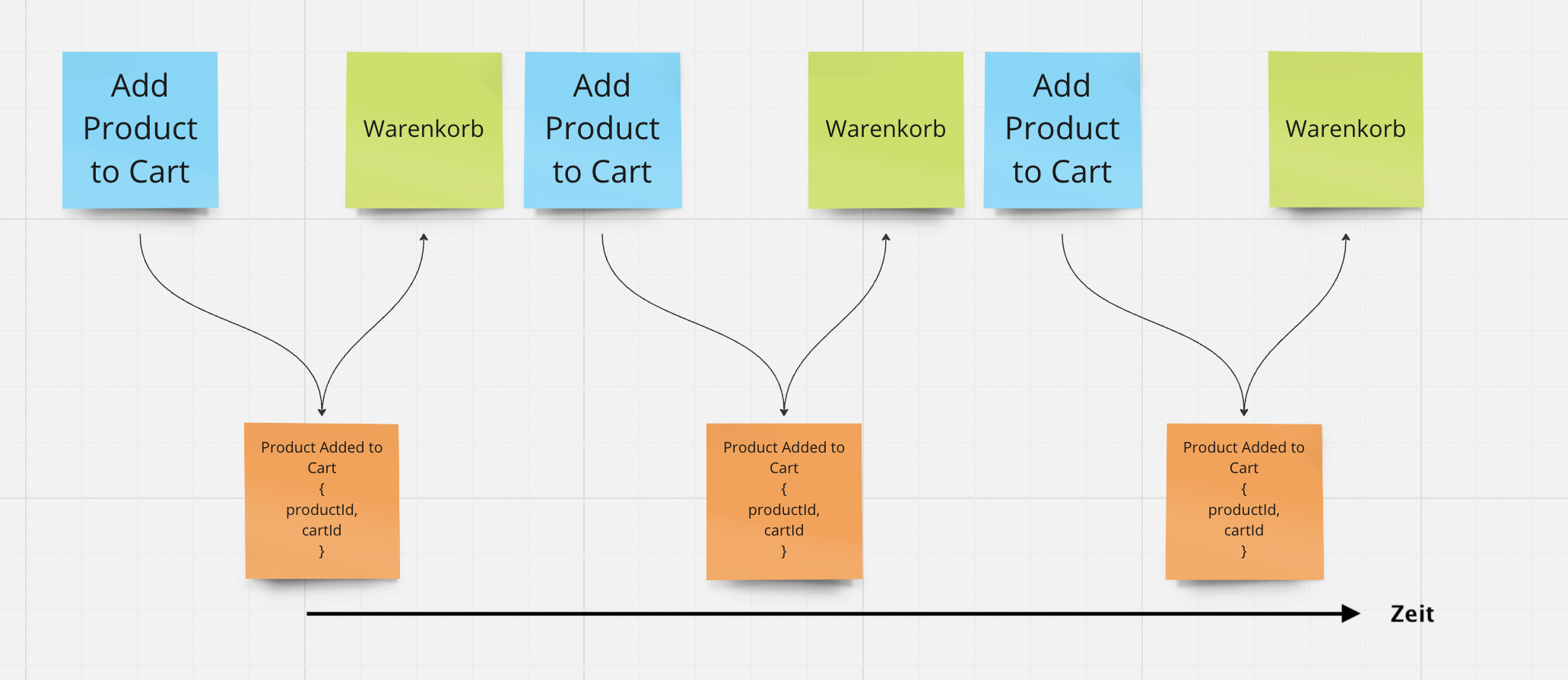
Important - the Event Model models time. We can always read it from left to right. Arrows never go back.
In addition to Commands, Events and Read Models, we use UI mockups (hand-drawn or from Figma)
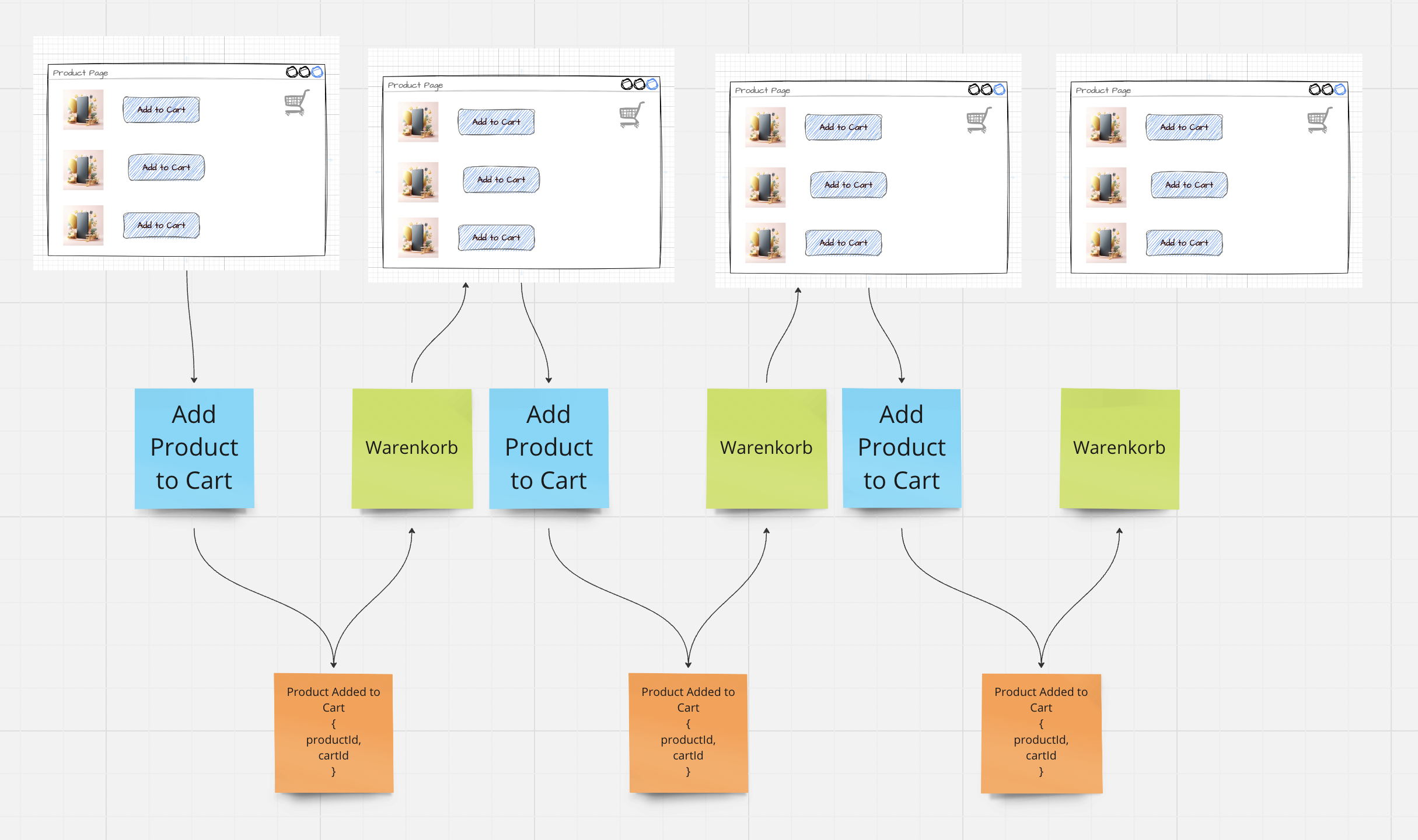
We arrange the Events in swim lanes and thus get a natural grouping (first hints at contexts in the system - the Bounded Context concept from Domain Driven Design)
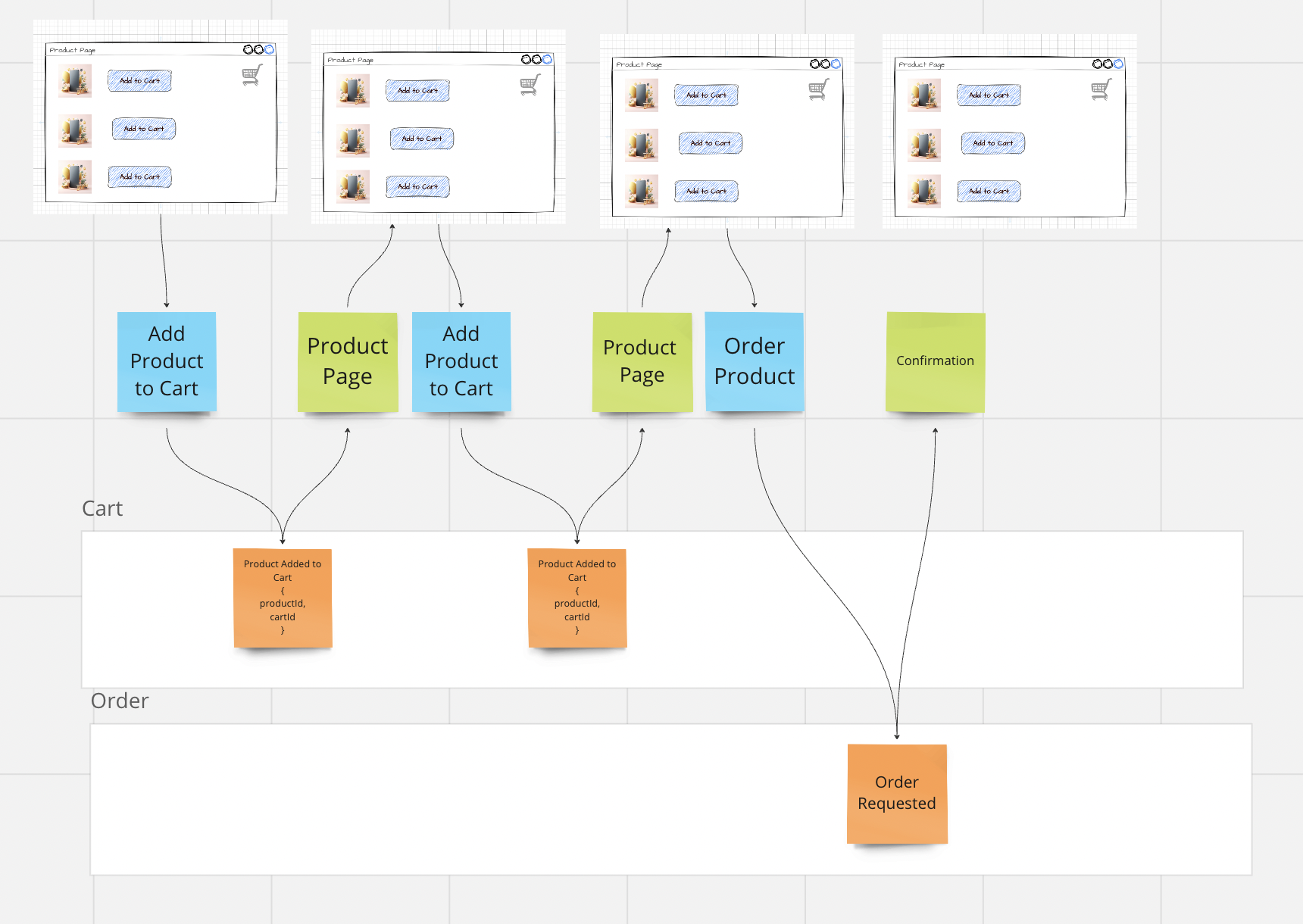
Through this type of arrangement, a natural division into Slices or functional blocks of our business emerges.
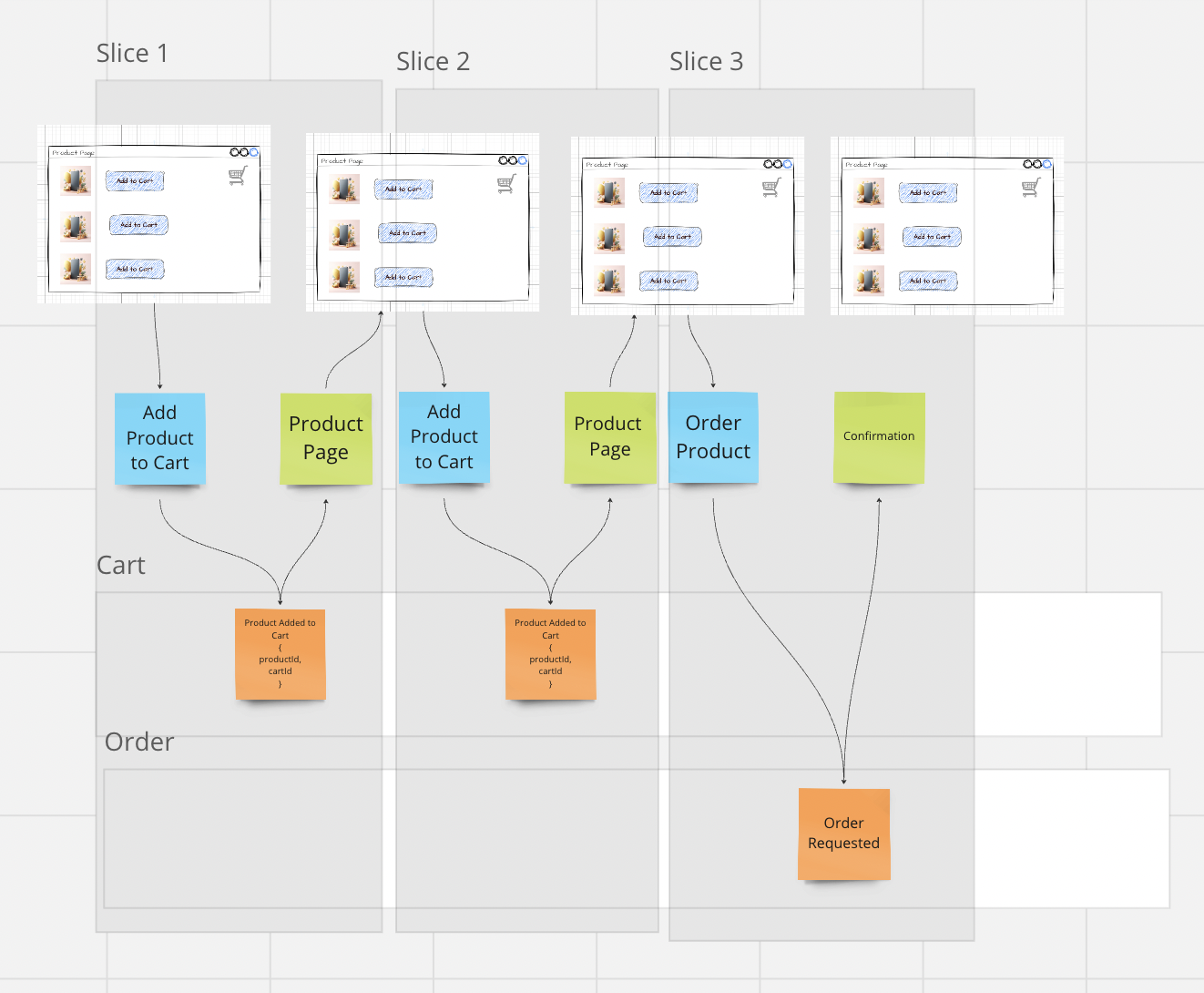
Slices usually consist of Command / Command Handler / Event and one or more Read Models. Slices are work packages that can be processed.
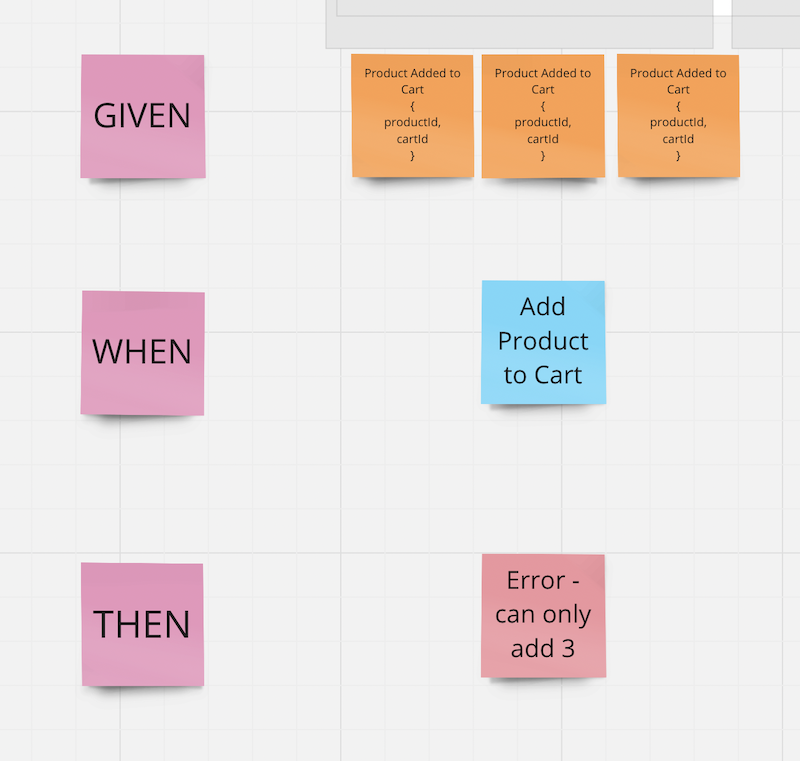
We model business rules via simple Given-When-Then Policies in the same model.
For example, here we see the rule that a maximum of 3 products can be added to the shopping cart.
The Event Model is the only place where the complete application including all business rules is visualized. In principle, we have a complete flow diagram including all side effects. So we can simply read the diagram from left to right.
With this we create:
Always up-to-date documentation
Perfect documentation for fast onboarding
Common understanding of how the software (and the business) works
Natural tasks through slices (slices could become user stories)
Documentation of all business rules
What’s Missing?
This article is not about implementing the system, but only about documenting how it works.
For implementing a first use case, the Event Model is already sufficient.
Some patterns are missing that are already described in fairly detail in Adam Dymitruk’s article.
The implementation of such a system works most easily with Event Sourcing, the process is most easily based on CQRS (Command Query Responsibility Segregation).
These concepts mesh seamlessly.
This is how you create IT documentation that everyone wants to read. Usable results after just one day. One thing I’ve learned in 15 years in the IT industry. Documentation of IT systems has always been difficult and that hasn’t changed in the last 15 years.
I can help document your IT system in a modern way.
- We use one document, not hundreds of pages in Confluence.
- The documentation accelerates every onboarding
- We document BEFORE development, not after.
Ready to Learn More?
My book “Understanding Eventsourcing” gives you the blueprint. But reading alone will take your team too long.
I can teach your team how to build these blueprints faster and skip the whole trial-and-error phase. Let’s have a chat about how this applies to your project.
Want to learn how to apply Event Modeling and Event Sourcing in practice?
Follow the Online Course “Implementing Eventsourcing” - comes with a Lifetime Event Modeling Toolkit License.