

There was a discussion in the Event Modeling community a few days ago that made me realize something: even after years of teaching this stuff, people still struggle with one fundamental question.
When should you NOT event source something?
It’s ironic, right? I’m known as the “event modeling guy.” Event sourcing is my default approach. I believe it makes everything simpler, clearer, more transparent. You always know what’s happening in your system.
But here’s the thing - sometimes, it’s not what you want to do.
And the distinction isn’t technical. It’s about meaning.
The Million-Record Problem
A few days ago, I was working with a team facing a classic integration scenario. Millions of records flooding in via Kafka from inventory locations worldwide. The question came up immediately:
“Should we event source all of these?”
My answer surprised them: No.
“What? you said Event Sourcing is your default. Shouldn´t it be yes?”
Of course, you COULD event source everything. The technology can handle it. But that’s not the point. The question isn’t “can we?” - it’s “should we?”
Here’s why we sometimes shouldn’t: An event marks a business-relevant change in your domain or system. A recorded decision made at some point in time. A “RecordImported” event? That’s not business-relevant. That´s not a decision. That’s just data showing up.
When Data Isn’t an Event
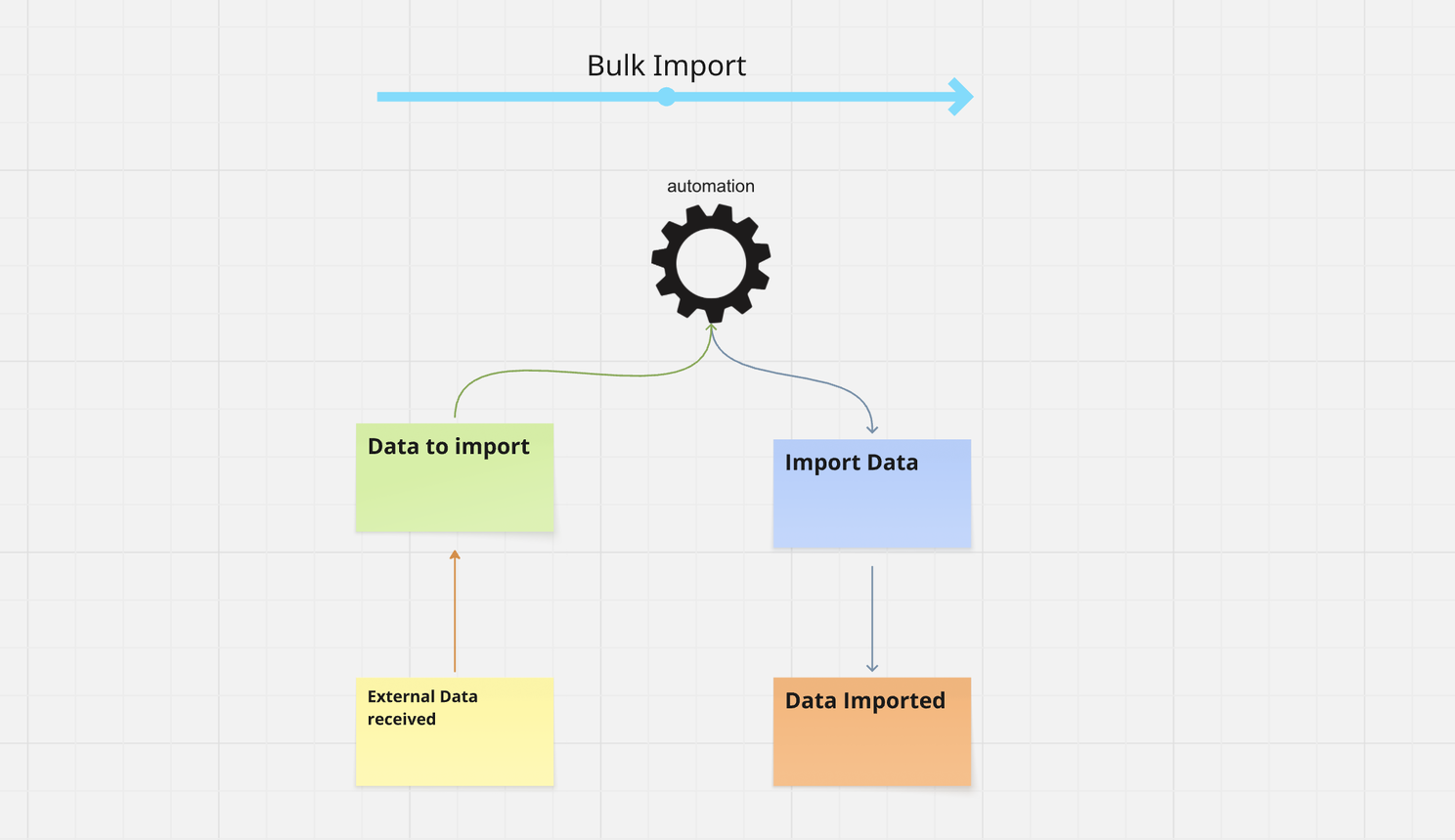
Think about it this way. Those millions of inventory records contain availability data from every location worldwide. Only a tiny fraction is relevant to any specific system at any point in time.
If you’re ordering from Munich, you don’t care about inventory in Chile. You care about what’s 80 kilometers away, not thousands.
You don’t even care about that Munich inventory until you actually need it. Which could be hours after the data was imported.
Until that moment, the imported information is just another Read Model in your system. It’s a source of information, not a source of change. It’s passive data, sitting in a table, waiting.
In the Event Model, this whole inventory system is just another green sticky note. Reference data. Nothing more.
Can you still model it? Of course you can! But it doesn´t mean, it´s event sourced.
The Moment Everything Changes
So when DOES it become an event?
When that passive data becomes active. When it affects your system’s behavior.
In our order processing system, we access that inventory information all the time. But accessing it isn’t an event. The event gets created when:
We’re out of inventory for an order (this affects fulfillment) We submit an order (this triggers a process) Inventory drops below a critical threshold (this triggers emergency management)
These are business-relevant changes. These drive behavior in the system.
But What About Proactive Monitoring?
Someone might argue: “Wait, Martin. What if we want to react proactively to inventory changes? Shouldn’t we event source those updates so we can monitor them?”
It depends..
Even proactive monitoring doesn’t require event sourcing the raw inventory data. You can monitor the inventory continuously by watching a table. Only when something crosses a threshold - only when it becomes business-relevant - do you fire an event.
In our solution, we processed millions of records using Kafka Connect and persisted them in our internal database, filtering on nearby locations. Then we had another process monitoring that database for critical thresholds using Change Data Capture.
When a threshold was crossed, THAT’S when we created an event. “EmergencyInventoryManagementRequired.” There´s a whole process behind that.
Those are real events. Those trigger processes. The raw inventory updates? Just data.
The Litmus Test
So how do you know what to event source and what to treat as reference data?
I use a simple test. I ask teams this question:
“An event is a recording of a decision made. If we shut down the system now and restart it in four hours, are we still interested in that decision?”
“RecordImported” fails this test. After a reboot, you don’t care that it was imported. You just care that the data exists in your table.
“Order Submitted” passes this test. After a reboot, you absolutely need to know that order was placed and needs fulfillment.
That’s the distinction.
Why This Matters
Here’s what’s interesting - you don’t figure this out through theory. You discover it through conversation.
During Event Modeling workshops, when we’re brainstorming and talking about events, talking about what happens in what order, the true events in your system reveal themselves.
What triggers processes? What do people actually care about? If there’s an event but nobody is using it, nobody is interested in it - why do we have it?
Of course, it’s not always black and white. There’s gray area here. Sometimes it makes sense to store events to answer questions for tomorrow.
But the principle is: Focus on “what is,” not “what could be.”
The Cost of “Just in Case”
Teams sometimes want to event source everything proactively. Especially Teams getting started are eager to have Events. Like back in the days, when the GoF Design Patterns came up. They were everywhere in Code - whether it made sense or not.
“But what if we want to react to inventory changes later? Shouldn’t we capture everything now?”
No.
Events don’t come for free. There’s cost. There’s throughput to consider. There’s complexity.
What’s relevant to your business right now? What are the events that trigger processes?
Answer those questions first.
And here’s the thing - if you get it wrong, you can always start event sourcing later. You’ll have the data from that point forward.
“But what about the historical data? The six months before we started event sourcing?”
That’s gone. But that’s also the nature of things. If you CRUD it, you lose it. Live with it. We did for decades. That’s a decision we made six months ago. We can’t revert it. We can only change it for the future.
The Mental Shift
Teams not used to events really struggle with this kind of thinking. It requires mental practice.
CRUD developers especially. They’re used to thinking about data existence. “Does this record exist? Yes or no?”
Event-driven thinking is different. It’s about behavioral change. It’s about decisions that matter. It’s about distinguishing between information sitting passively in a table and events that drive your system forward.
That shift doesn’t happen overnight. It takes practice. It takes conversation. It takes working through real examples in workshops until the lightbulb goes on.
The Practical Path Forward
Here’s my approach with teams:
Don’t event source everything. Process your bulk data with simpler, more appropriate tools. Kafka Connect. Database tables. Batch jobs.
Create events only when they trigger business processes. When they represent decisions that matter. When they change how your system behaves.
Reference data sits in tables. Events drive behavior.
And if you realize later you need to event source something you didn’t before? Start then. Accept that you don’t have the history. Make better decisions going forward.
Better to make a clear decision now than to over-engineer for hypothetical futures.
The Core Principle
An event is a business-relevant change in your domain or system.
Not every data change is a business change.
Not every import is an event.
Not every update matters.
Your job in Event Modeling workshops is to discover which changes actually drive your system. Which decisions need to be recorded. Which moments need to be captured forever.
The rest? That’s just data.
This distinction - between events and reference data, between passive information and active change - this is what separates systems that scale from systems that collapse under their own weight.
It’s what the discussion in the Event Modeling community was really about.
And it’s what I’ll keep teaching, one workshop at a time, until this way of thinking becomes second nature.
Because once you see it, you can’t unsee it.
Martin Dilger is the founder of Nebulit and a recognized expert in Event Modeling and event-driven architectures. He helps teams distinguish between events and reference data, building systems that scale without unnecessary complexity.
Learn Event Modeling from the experts
Join the Event Modeling Hands-On Workshop on March 16/17 — learn how to design systems that are honest from the start.
Want to learn how to apply Event Modeling and Event Sourcing in practice?
Follow the Online Course “Implementing Eventsourcing” - comes with a Lifetime Event Modeling Toolkit License.