

“How do I structure my codebase so an AI can read it?” That question is everywhere right now. And I think it’s the wrong one.
The right question is: how do you make isolated capabilities accessible without requiring full comprehension of the system?
We had a discussion about structure yesterday, and it’s good to have those discussions.
That’s exactly what slice-based architecture does. And most developers have never seen it in real life.
The Wrong Instinct
Take something simple. Customer registration. A traditional developer hears those two words and their brain immediately fires: Customer entity, Registration table, domain logic, service layer. Horizontal layers, top to bottom. It’s almost a reflex.
In a slice-based approach, you do it completely differently.
You start with one slice: “Register Customer.” That’s your only focus. This single slice fully describes how a customer enters the system - from the UI, through the logic, all the way to persistence. It describes nothing else. The slice stops exactly where the information becomes available. Complete in itself.
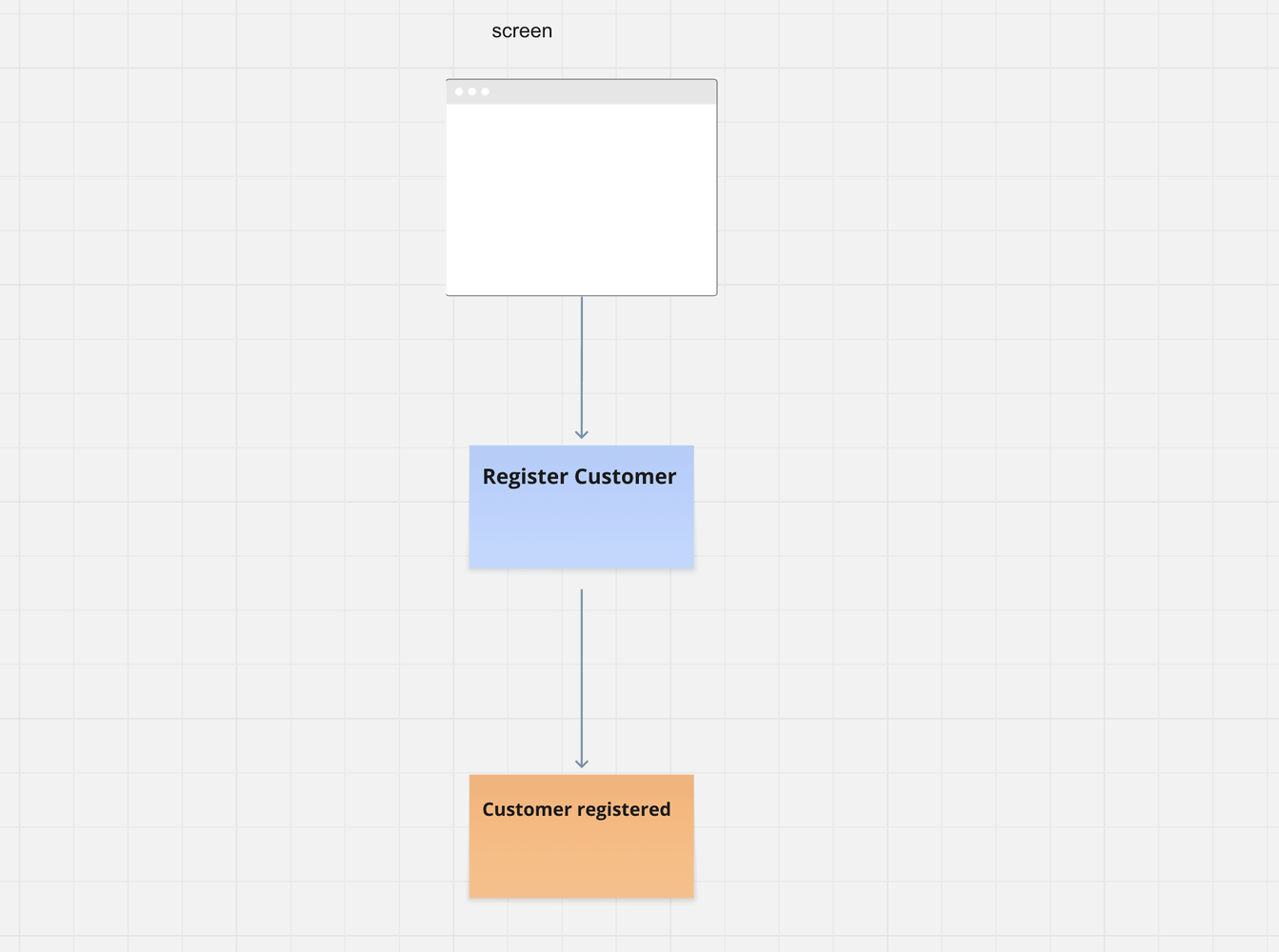
Done.
Then you build the next slice. Typically describing how this information is used. And the next. Each one a tiny, self-contained business capability.
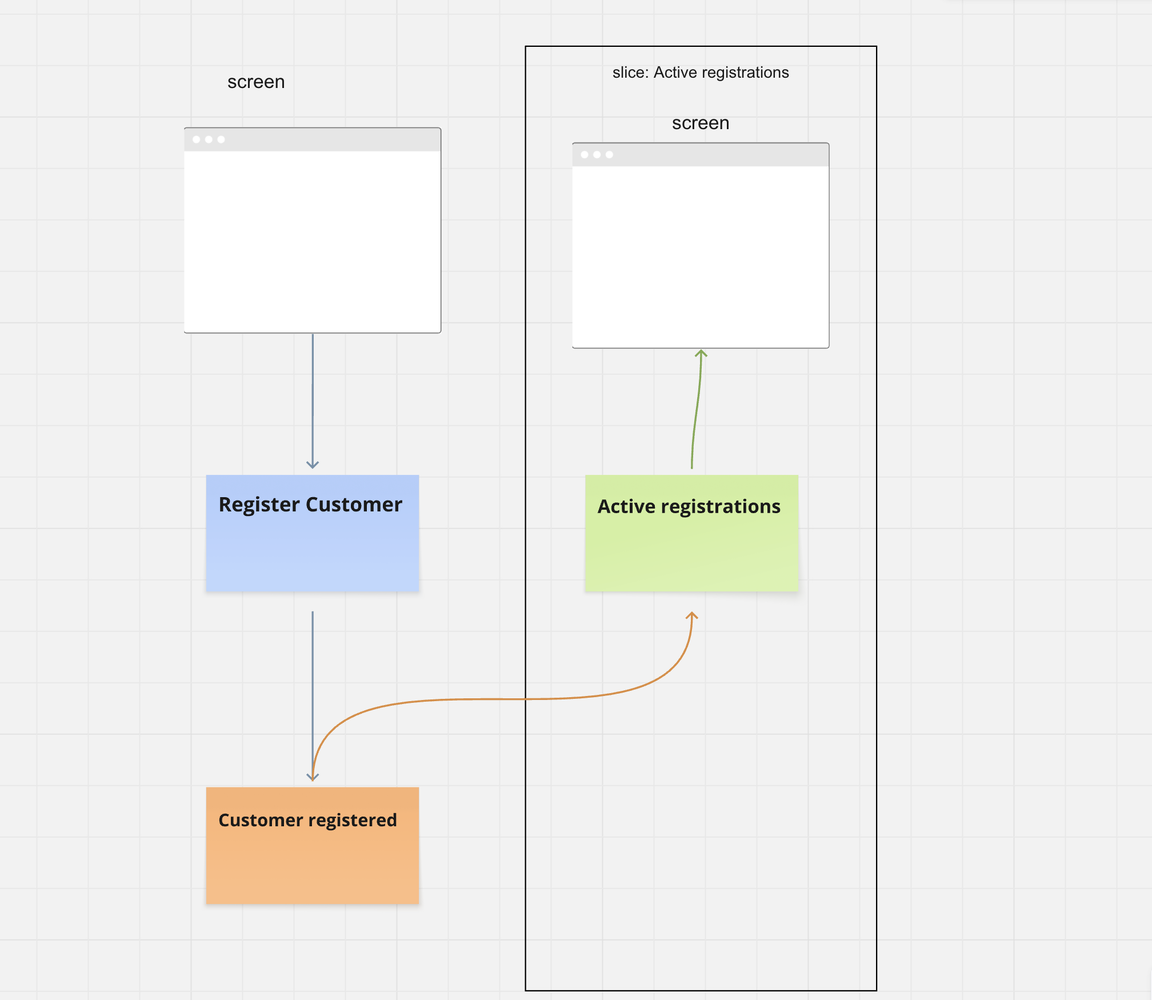
And here’s where most people hit a wall.
You Won’t See the Forest for the Trees

Wait a second - with all those slices - how do you navigate the code base? Because yes, every slice becomes a package or a folder in your code base.
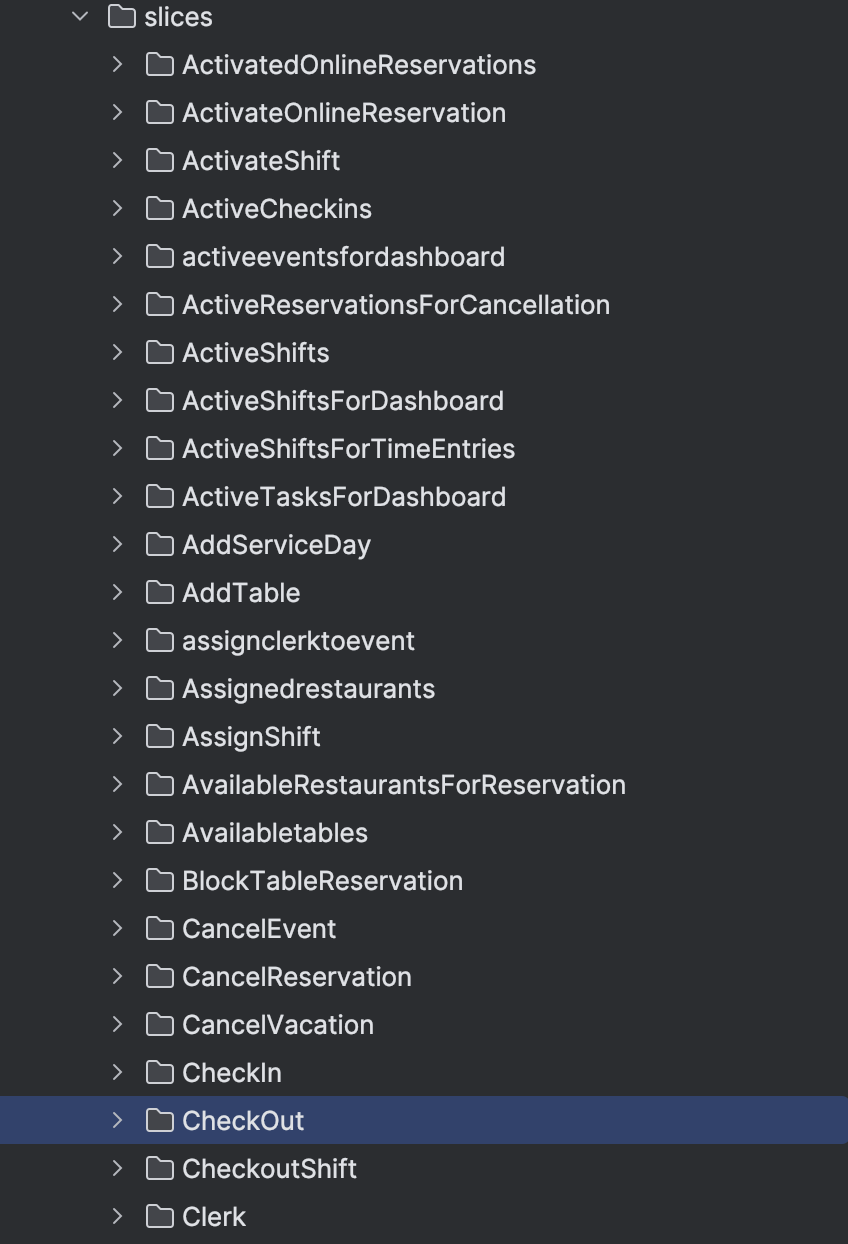
As the list of slices grows, it starts to look chaotic. I felt this myself on my first slice-based system. Staring at this expanding list of capabilities thinking: this is never going to work. You’ll lose yourself in here.
But then something strange happened.
The growing list looked chaotic - but it wasn’t. Because you literally never look at the list. N.E.V.E.R.
You only ever work on one slice at a time. You go to the event model, you make your adjustments, and you jump directly to that slice. It doesn’t matter where the slice lives. It doesn’t matter how many others exist. Complete focus on one thing.
The Map and the Road
This is why slice-based architectures and event modeling go hand in hand. The event model is the map. The code is just the road you are on. Without the map, you lose yourself.
An LLM never needs to read the whole codebase. That’s where most teams lose a lot of time. It navigates directly to the exact slice it needs. And it never needs more than one. Think about what that means for your token budget. Think about accuracy, context window management, code quality.
The LLM literally looks at 4-6 files per task, never more.
The event model is a precision index. And that’s not a workaround - that’s the architectural advantage.
One Data Source, Many Slices
Back to customer registration. The write side is one slice. But now you need to display that data - in the admin dashboard, in the welcome email flow, in the billing overview.
Traditional instinct: one view, one source of truth, share it.
That’s the hard part for most developers.
Slice-based: each display is its own slice. Same underlying data, different projection, different question asked of that data.
Here’s what that looks like in practice. For the billing Dashboard, we need registration dates with timezone. In a traditional shared view, you are now starting to debate the change, because changing the shared table means changing all features that use it. In a slice-based system, you go to the billing projection slice, make the change, done. The admin dashboard never knew it happened.
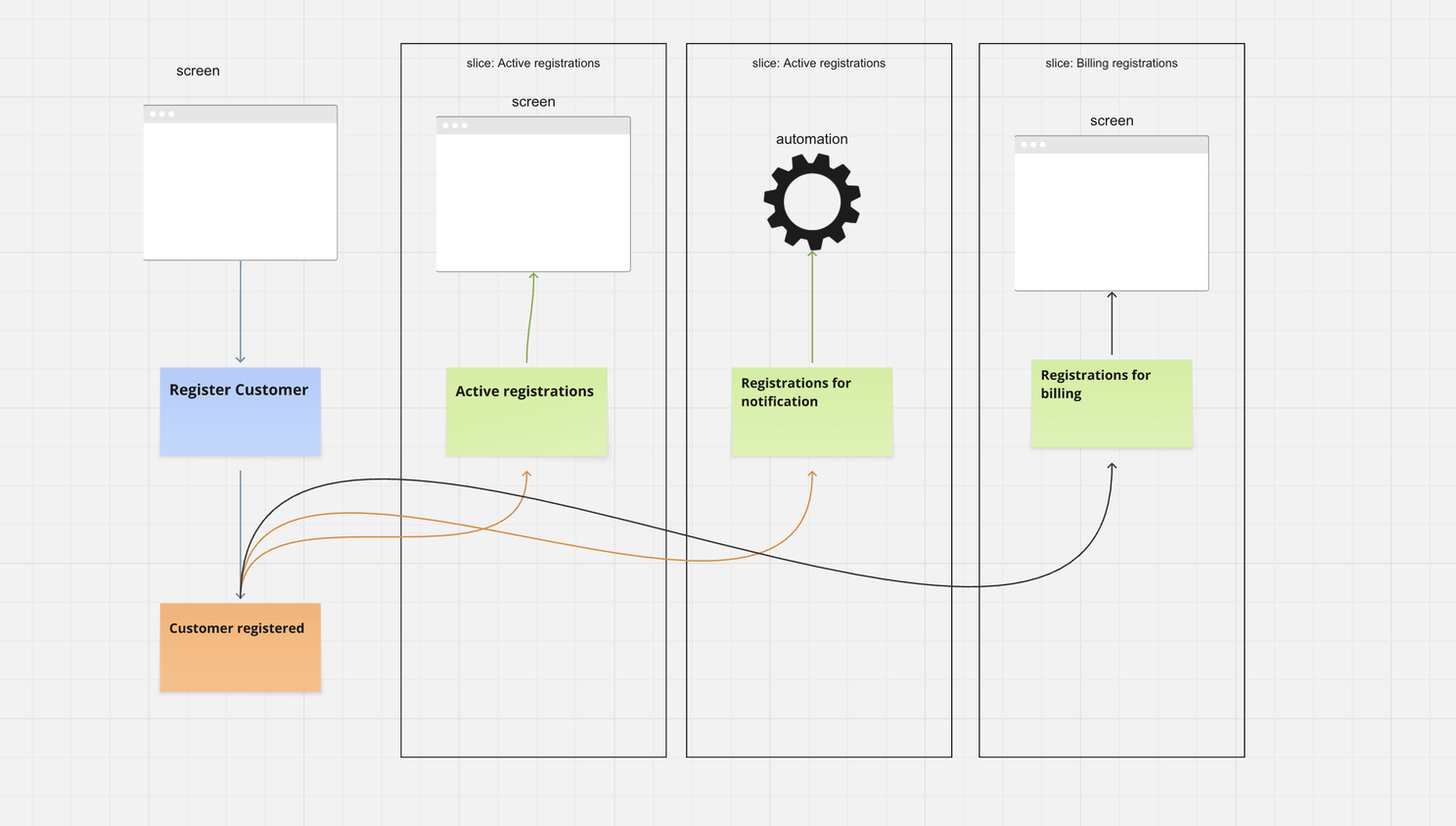
No Bottlenecks
The goal the whole system is built around: any person - or any AI - should walk into the project, pick up one slice, and be productive immediately. No need to understand everything. No single person holding all the context in their head.
Most developers wear “being the only one who understands the system” as a badge of honor. I’ve been that person. Rockstar status feels like power. It’s actually a trap. You become the bottleneck. Nothing moves without you.
And you burn half of your context window just to understand what needs to be done.
Slice-based architecture breaks that trap by design.
On Folder Structure
I’m not religious about this. Clean code looks better. Structured code bases look better - of course they do. But in practice - your beautiful structure might be waste to some extent - as nobody will ever look at it. You always navigate slices - not by browsing folders.
The more coupling exists in the system, the more structure you need. Slices decouple - that’s why structure doesn’t really matter too much beyond slices.
I use 4 structural layers in Event Modeling. Contexts - Chapters - Slices - Elements
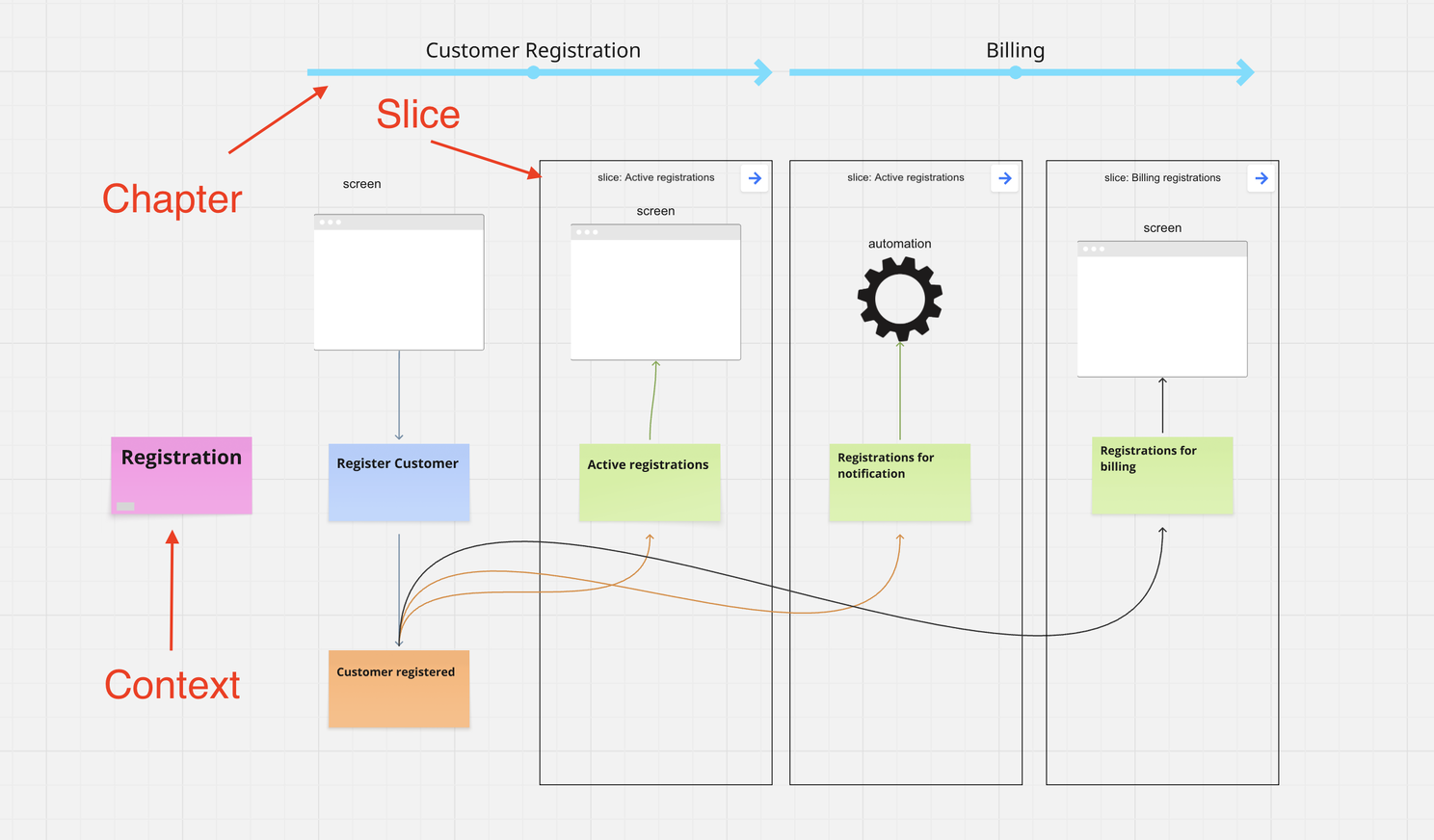
It’s easy to optimize the wrong thing. Whether you apply this structure to your code base is a matter of taste, not necessarily a matter of productivity.
I literally have in my prompt clear instructions that the AI must never look at anything outside the currently assigned slice. The whole world literally consists of one folder for the time being.
The chaos you see when looking at a long list of slices is an illusion. The system was never designed to be understood as a whole. You just need enough context to fit one slice. It was designed to be worked on one capability at a time, with a map that tells you exactly where to go.
That’s not a limitation. That’s the whole point.
The Question
Does your AI need to understand the code base before doing anything? What’s your thoughts?
The traditional answer has been yes - the AI needs to read through files, understand relationships, trace dependencies. That’s why teams invest in better prompts, more context, longer token windows.
But with slice-based architecture, the answer changes to no. The AI doesn’t need to understand the whole system. It only needs to understand one slice. And the event model tells it exactly which slice, what that slice does, and where to find it.
That’s not just faster. That’s a fundamentally different way of working.
Learn Event Modeling from the experts
Join the Event Modeling Hands-On Workshop on March 16/17 — learn how to design systems that are honest from the start.
Want to learn how to apply Event Modeling and Event Sourcing in practice?
Follow the Online Course “Implementing Eventsourcing” - comes with a Lifetime Event Modeling Toolkit License.